Output space exploration
Output space exploration is a form of optimization based on novelty search. In the workbench, it relies on the optimization functionality. You can use output space exploration by passing an instance of either OutputSpaceExplorationAlgorithm or AutoAdaptiveOutputSpaceExplorationAlgorithm as algorithm to evaluator.optimize. The fact that output space exploration uses the optimization functionality also implies that we can track convergence in a similar manner. Epsilon progress is
defined identical, but evidently other metrics such as hypervolume might not be applicable in the context of output space exploration.
The difference between OutputSpaceExplorationAlgorithm and AutoAdaptiveOutputSpaceExplorationAlgorithm is in the evolutionary operators. AutoAdaptiveOutputSpaceExplorationAlgorithm uses auto adaptive operator selection as implemented in the BORG MOEA, while OutputSpaceExplorationAlgorithm by default uses Simulated Binary crossover with polynomial mutation. Injection of new solutions is handled through auto adaptive population sizing and periodically starting with a new population
if search is stalling. Below, examples are given of how to use both algorithms, as well as a a quick visualization of the convergence dynamics.
For this example, we are using a stylized case study frequently used to develop and test decision making under deep uncertainty methods: the shallow lake problem. In this problem, a city has to decide on the amount of pollution they are going to put into a shallow lake per year. The city gets benefits from polluting the lake, but if an unknown threshold is crossed, the lake permanently shifts to an undesirable polluted state. For further details on this case study, see for example Quinn et al, 2017 and Bartholomew et al, 2021.
[1]:
import pandas as pd
from lake_models import lake_problem_intertemporal
from ema_workbench import (
Constant,
Model,
MultiprocessingEvaluator,
OutputSpaceExplorationAlgorithm,
RealParameter,
Sample,
ScalarOutcome,
ema_logging,
)
[2]:
ema_logging.log_to_stderr(ema_logging.INFO)
# instantiate the model
lake_model = Model("lakeproblem", function=lake_problem_intertemporal)
lake_model.time_horizon = 100
# specify uncertainties
lake_model.uncertainties = [
RealParameter("b", 0.1, 0.45),
RealParameter("q", 2.0, 4.5),
RealParameter("mean", 0.01, 0.05),
RealParameter("stdev", 0.001, 0.005),
RealParameter("delta", 0.93, 0.99),
]
# set levers, one for each time step
lake_model.levers = [
RealParameter(f"l{i}", 0, 0.1) for i in range(lake_model.time_horizon)
]
# specify outcomes
# output space exploration
lake_model.outcomes = [
ScalarOutcome("max_P", kind=ScalarOutcome.MAXIMIZE),
ScalarOutcome("utility", kind=ScalarOutcome.MAXIMIZE),
ScalarOutcome("inertia", kind=ScalarOutcome.MAXIMIZE),
ScalarOutcome("reliability", kind=ScalarOutcome.MAXIMIZE),
]
# override some of the defaults of the model
lake_model.constants = [Constant("alpha", 0.41), Constant("nsamples", 150)]
Above, we have setup the lake problem, specified the uncertainties, policy levers, outcomes of interest and (optionally) some constants. We are now ready to run output space exploration on this model. For this, we use the default optimization functionality of the world bank, but pass the OutputSpaceExploration class. Below, we are running output space exploration over the uncertainties, which implies we need to pass a reference policy. We also rerun the algorithm for 5 different seeds. We
can track convergence of the outputspace epxloration by tracking \(\epsilon\)-progress.
The grid_spec keyword argument, which is specific to output space exploration specifies the grid structure we are imposing on the output space. There must be a tuple for each outcome of interest. Each tuple specifies the minimum value, the maximum value and the size of the grid cell on this outcome dimension.
[3]:
import time
# generate some default policy
reference = Sample("nopolicy", **{lever.name: 0.02 for lever in lake_model.levers})
n_seeds = 5
convergences = []
with MultiprocessingEvaluator(lake_model) as evaluator:
for _ in range(n_seeds):
seed = time.time()
results, convergence_info = evaluator.optimize(
algorithm=OutputSpaceExplorationAlgorithm,
grid_spec=[(0, 12, 0.5), (0, 0.6, 0.05), (0, 1, 0.1), (0, 1, 0.1)],
nfe=25000,
searchover="uncertainties",
reference=reference,
filename=f"lake_model_output_space_exploration_seed_{seed}.tar.gz",
directory="./data",
rng=seed,
)
convergences.append(convergence_info)
[MainProcess/INFO] pool started with 10 workers
28000it [00:23, 1199.97it/s]
[MainProcess/INFO] optimization completed, found 1375 solutions
27685it [00:22, 1243.24it/s]
[MainProcess/INFO] optimization completed, found 1383 solutions
27970it [00:22, 1229.75it/s]
[MainProcess/INFO] optimization completed, found 1360 solutions
28390it [00:22, 1245.23it/s]
[MainProcess/INFO] optimization completed, found 1407 solutions
28300it [00:22, 1242.28it/s]
[MainProcess/INFO] optimization completed, found 1392 solutions
[MainProcess/INFO] terminating pool
[4]:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("whitegrid")
fig, ax = plt.subplots()
for convergence in convergences:
ax.plot(convergence.nfe, convergence.epsilon_progress)
ax.set_xlabel("nfe")
ax.set_ylabel(r"$\epsilon$-progress")
plt.show()
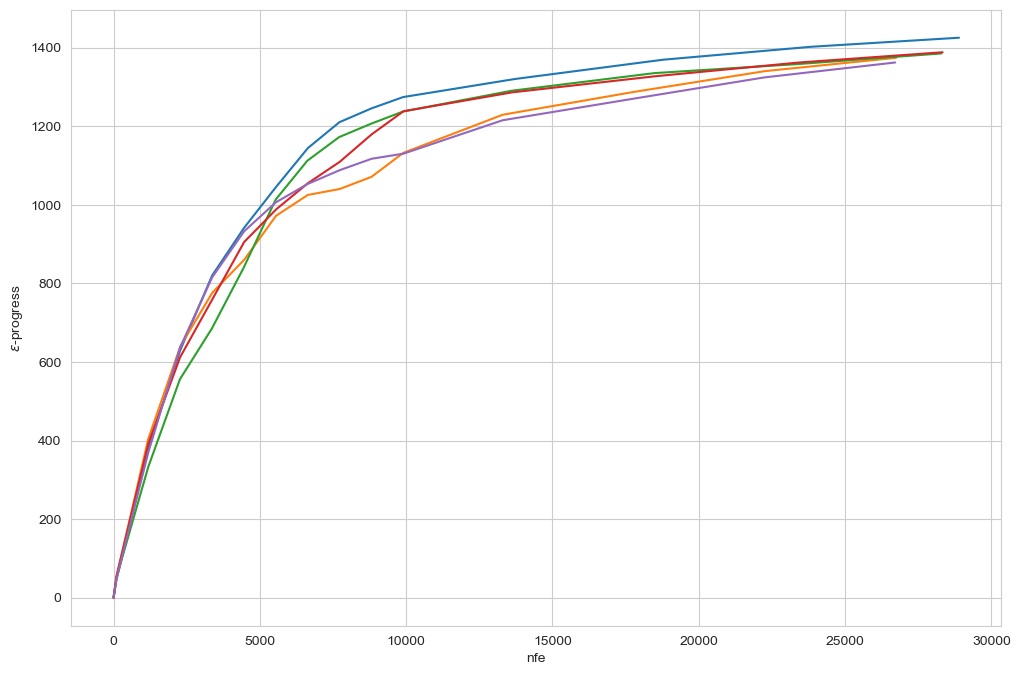
The figure above shows the \(\epsilon\)-progress per nfe for each of the five random seeds. As can be seen, the algorithm converges to essentially the same amount of epsilon progress across the seeds. This suggests that the algorithm has converged and thus found all possible output grid cells.
auto adaptive operator selection
The foregoing example used the default version of the output space exploration algorithm. This algorithm uses Simulated Binary Crossover (SBX) with Polynomial Mutation (PM) as its evolutionary operators. However, it is conceivable that for some problems other evolutionary operators might be more suitable. You can pass your own combination of operators if desired using platypus. For general use, however, it can sometimes be easier to let the
algorithm itself figure out which operators to use. To support this, we also provide an AutoAdaptiveOutputSpaceExploration algorithm. This algorithm uses Auto Adaptive Operator selection as also used in the BORG algorithm. Note that this algorithm is limited to RealParameters only.
[5]:
from ema_workbench.em_framework.outputspace_exploration import (
AutoAdaptiveOutputSpaceExplorationAlgorithm,
)
convergences = []
with MultiprocessingEvaluator(lake_model) as evaluator:
for _ in range(5):
seed = time.time()
results, convergence_info = evaluator.optimize(
algorithm=AutoAdaptiveOutputSpaceExplorationAlgorithm,
grid_spec=[(0, 12, 0.5), (0, 0.6, 0.05), (0, 1, 0.1), (0, 1, 0.1)],
nfe=25000,
searchover="uncertainties",
reference=reference,
filename=f"lake_model_output_space_exploration__autoadaptive_seed_{seed}.tar.gz",
directory="./data",
rng=seed,
)
convergences.append(convergence_info)
[MainProcess/INFO] pool started with 10 workers
25087it [00:21, 1152.90it/s]
[MainProcess/INFO] optimization completed, found 1445 solutions
29578it [00:25, 1173.57it/s]
[MainProcess/INFO] optimization completed, found 1442 solutions
30207it [00:26, 1141.19it/s]
[MainProcess/INFO] optimization completed, found 1450 solutions
30102it [00:26, 1151.28it/s]
[MainProcess/INFO] optimization completed, found 1440 solutions
30150it [00:26, 1126.20it/s]
[MainProcess/INFO] optimization completed, found 1448 solutions
[MainProcess/INFO] terminating pool
[6]:
sns.set_style("whitegrid")
fig, ax = plt.subplots()
for convergence in convergences:
ax.plot(convergence.nfe, convergence.epsilon_progress)
ax.set_xlabel("nfe")
ax.set_ylabel(r"$\epsilon$-progress")
plt.show()
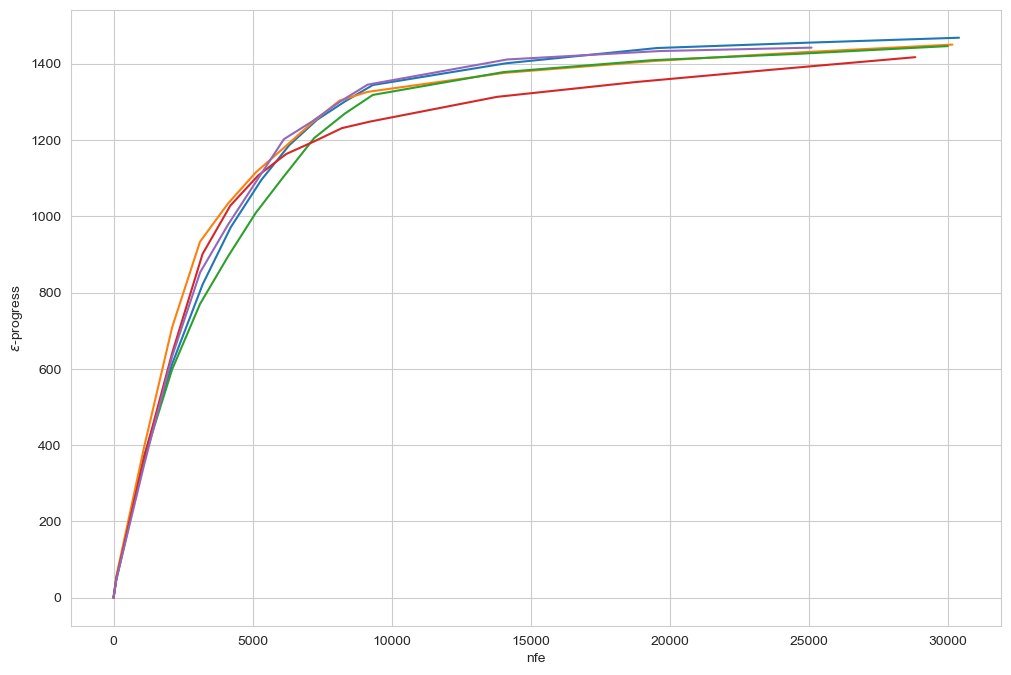
Above, you see the \(\epsilon\)-convergence for the auto adaptive operator selection version of the outputspace algorithm. Like the normal version, it converges to essential the same number across the different seeds. Note also that the \(\epsilon\)-progress is slightly higher, and also the total number of identified solutions (see log messages) is higher. That suggests that for even for a relatively simple problem, there is value in using the auto adaptive operator selection.
In case of AutoAdaptiveOutputSpaceExplorationAlgorithm it can sometimes also be revealing to check the dynamics of the operators over the evolution. This is shown below separately for each seed. For the meaning of the abbreviations, check the BORG algorithm.
[11]:
for convergence in convergences:
fig, ax = plt.subplots()
ax.plot(convergence.nfe, convergence.SBX, label="SBX")
ax.plot(convergence.nfe, convergence.PCX, label="PCX")
ax.plot(
convergence.nfe,
convergence.DifferentialEvolution,
label="DifferentialEvolution",
)
ax.plot(convergence.nfe, convergence.UNDX, label="UNDX")
ax.plot(convergence.nfe, convergence.SPX, label="SPX")
ax.plot(convergence.nfe, convergence.UM, label="UM")
ax.legend()
plt.show()
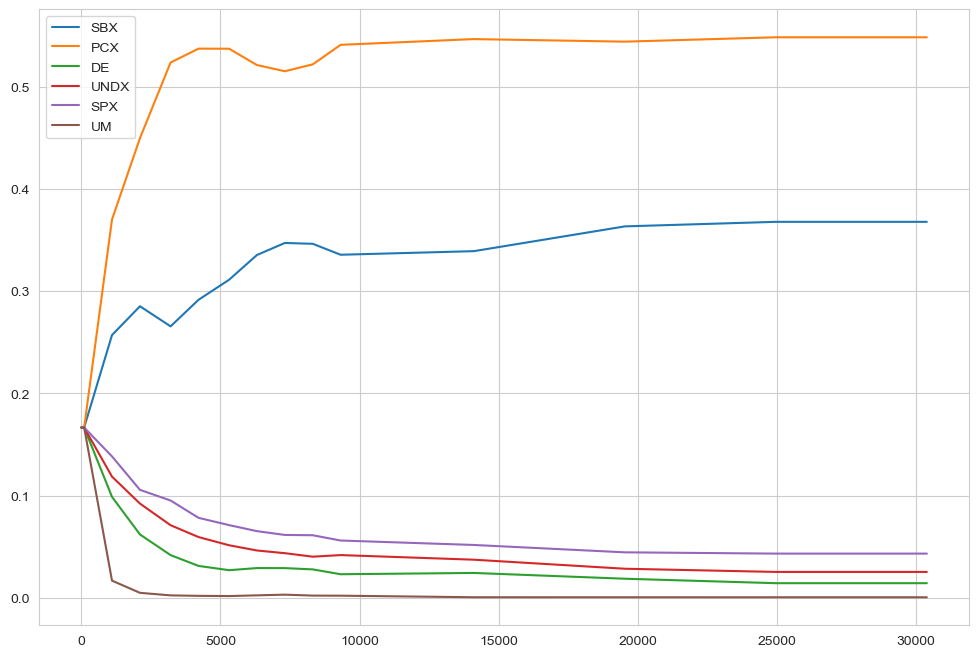
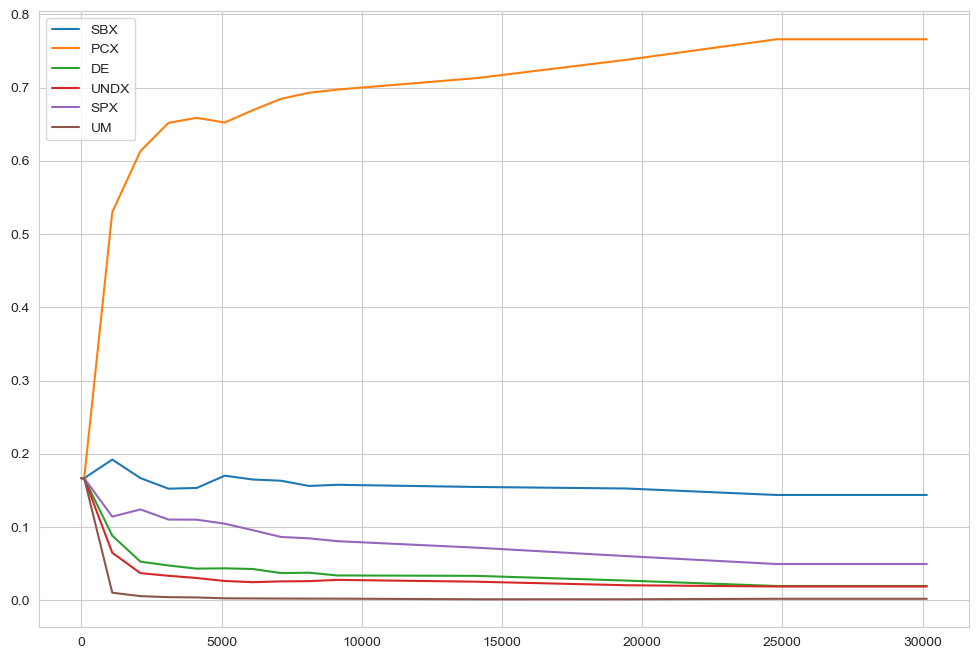
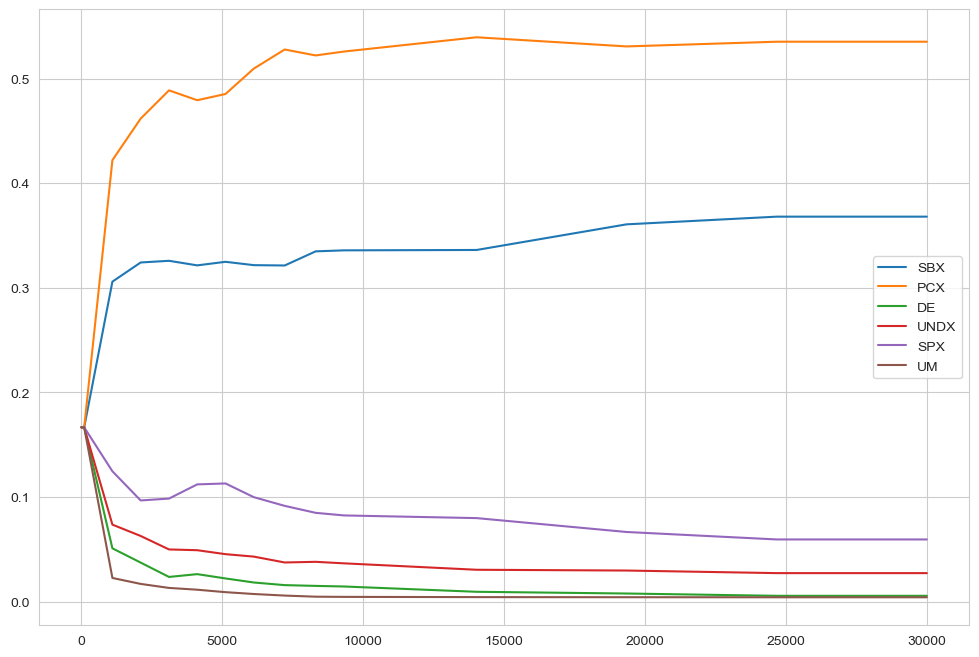
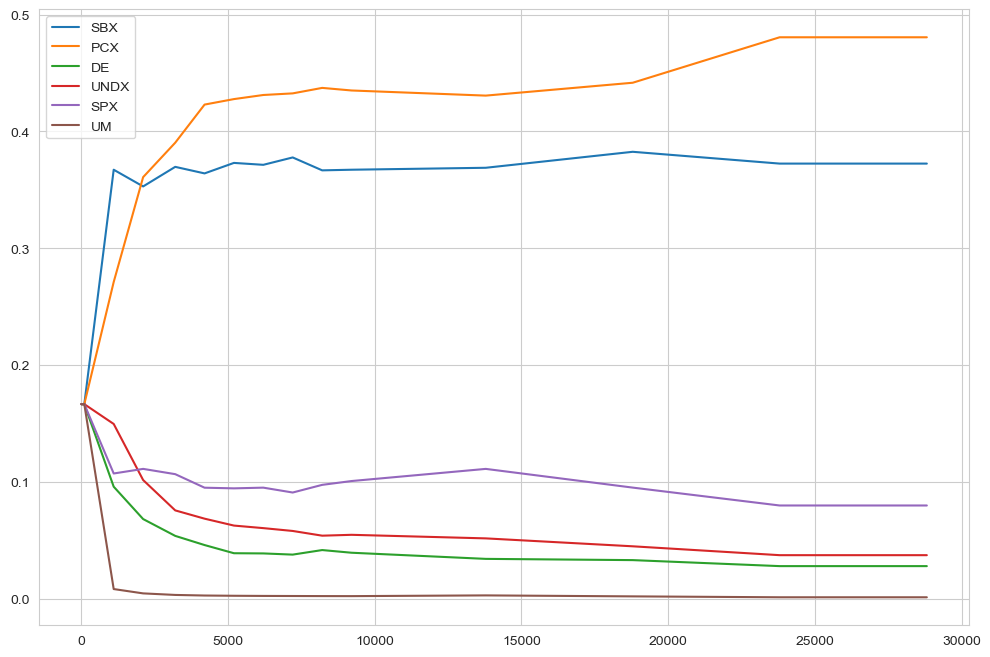
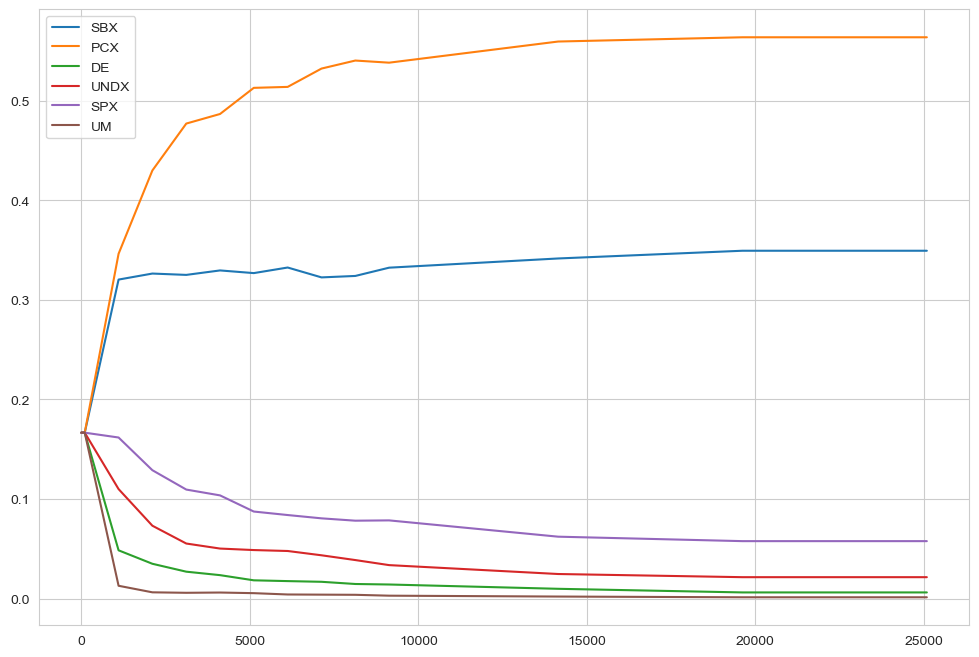
LHS
for comparison, let’s also generate a Latin Hypercube Sample and compare the results. Since the output space exploration return close to 1500 solutions, we use 1500 for LHS as well.
[12]:
with MultiprocessingEvaluator(lake_model) as evaluator:
experiments, outcomes = evaluator.perform_experiments(
scenarios=1500, policies=reference
)
[MainProcess/INFO] pool started with 10 workers
[MainProcess/INFO] performing 1500 scenarios * 1 policies * 1 model(s) = 1500 experiments
100%|████████████████████████████████████| 1500/1500 [00:00<00:00, 5139.29it/s]
[MainProcess/INFO] experiments finished
[MainProcess/INFO] terminating pool
comparison
Below we compare the LHS with the last seed of the autoadaptive algorithm. Remember, the purpose of output space exploration is to identify the kinds of behavior that a model can show given a set of uncertain parameters. So, we are creating a pairwise scatter plot of the outcomes for both output space exploration (in blue) and the latin hypercube sampling (in orange).
[13]:
outcomes = pd.DataFrame(outcomes)
outcomes["sampling"] = "LHS"
[15]:
ose = results.iloc[:, 5::].copy()
ose["sampling"] = "OSE"
[16]:
data = pd.concat([ose, outcomes], axis=0, ignore_index=True)
[17]:
# sns.pairplot(data, hue='sampling')
sns.pairplot(data, hue="sampling", vars=data.columns[0:4])
plt.show()
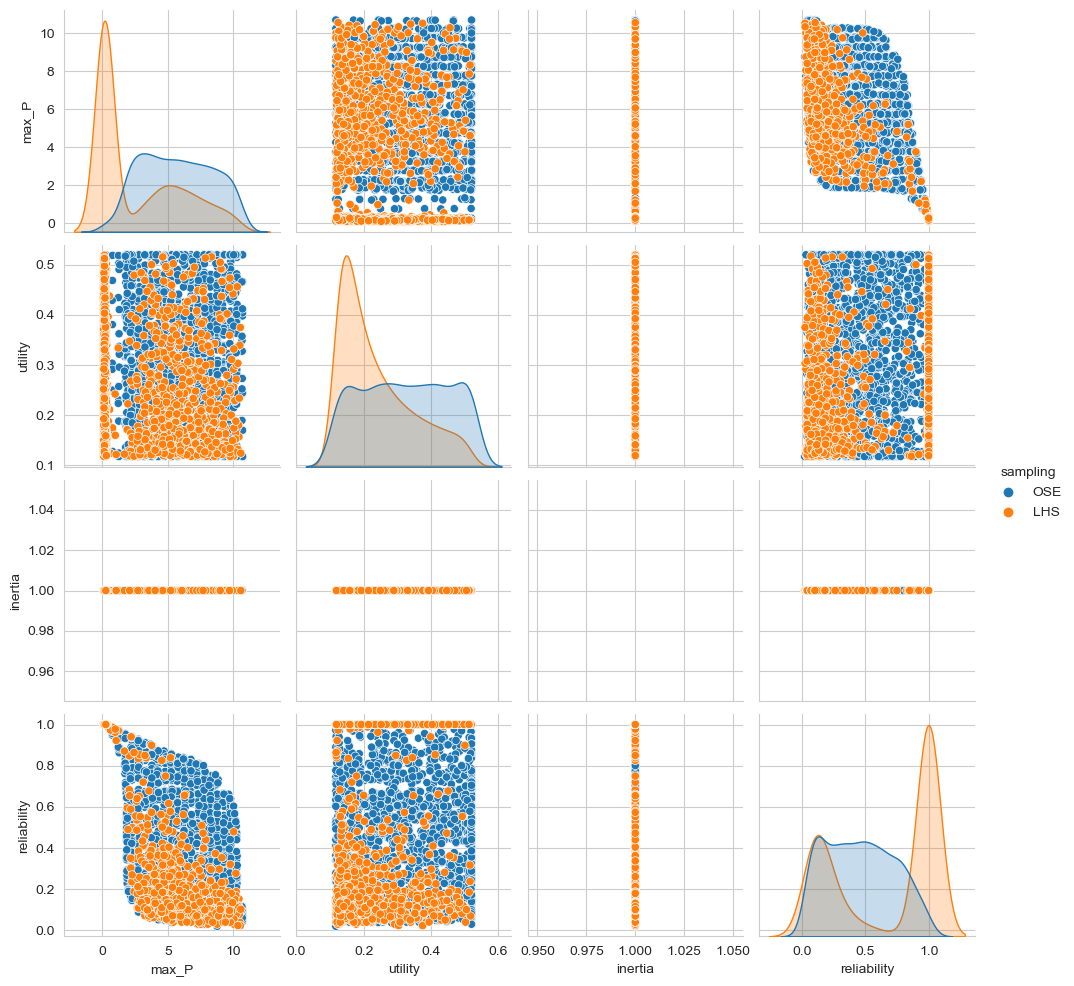
As you can clearly see, the output space exploration algorithm has uncovered behaviors that were not seen in the 1500 sample LHS.
[ ]: