Tutorials
The code of these examples can be found in the examples package. The first three examples are meant to illustrate the basics of the EMA workbench. How to implement a model, specify its uncertainties and outcomes, and run it. The fourth example is a more extensive illustration based on Pruyt & Hamarat (2010). It shows some more advanced possibilities of the EMA workbench, including one way of handling policies.
A simple model in Python
The simplest case is where we have a model available through a python function. For example, imagine we have the simple model.
def some_model(x1=None, x2=None, x3=None):
return {'y':x1*x2+x3}
In order to control this model from the workbench, we can make use of the
Model. We can instantiate a model
object, by passing it a name, and the function.
model = Model('simpleModel', function=some_model) #instantiate the model
Next, we need to specify the uncertainties and the outcomes of the model. In this case, the uncertainties are x1, x2, and x3, while the outcome is y. Both uncertainties and outcomes are attributes of the model object, so we can say
1#specify uncertainties
2model.uncertainties = [RealParameter("x1", 0.1, 10),
3 RealParameter("x2", -0.01,0.01),
4 RealParameter("x3", -0.01,0.01)]
5#specify outcomes
6model.outcomes = [ScalarOutcome('y')]
Here, we specify that x1 is some value between 0.1, and 10, while both x2 and x3 are somewhere between -0.01 and 0.01. Having implemented this model, we can now investigate the model behavior over the set of uncertainties by simply calling
results = perform_experiments(model, 100)
The function perform_experiments() takes the model we just specified
and will execute 100 experiments. By default, these experiments are generated
using a Latin Hypercube sampling, but Monte Carlo sampling and Full factorial
sampling are also readily available. Read the documentation for
perform_experiments() for more details.
The complete code:
1"""An illustrationo of how to use the workbench with models in python."""
2
3from ema_workbench import (
4 Model,
5 RealParameter,
6 ScalarOutcome,
7 ema_logging,
8 perform_experiments,
9)
10
11# Created on 20 dec. 2010
12#
13# .. codeauthor:: jhkwakkel <j.h.kwakkel (at) tudelft (dot) nl>
14
15
16def some_model(x1=None, x2=None, x3=None):
17 """Some model."""
18 return {"y": x1 * x2 + x3}
19
20
21if __name__ == "__main__":
22 ema_logging.LOG_FORMAT = "[%(name)s/%(levelname)s/%(processName)s] %(message)s"
23 ema_logging.log_to_stderr(ema_logging.INFO)
24
25 model = Model("simpleModel", function=some_model) # instantiate the model
26
27 # specify uncertainties
28 model.uncertainties = [
29 RealParameter("x1", 0.1, 10),
30 RealParameter("x2", -0.01, 0.01),
31 RealParameter("x3", -0.01, 0.01),
32 ]
33 # specify outcomes
34 model.outcomes = [ScalarOutcome("y")]
35
36 results = perform_experiments(model, 100)
A simple model in Vensim
Imagine we have a very simple Vensim model:
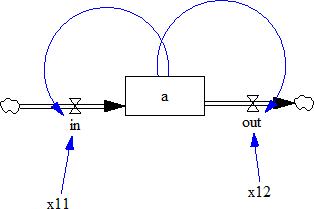
For this example, we assume that ‘x11’ and ‘x12’ are uncertain. The state
variable ‘a’ is the outcome of interest. Similar to the previous example,
we have to first instantiate a vensim model object, in this case
VensimModel. To this end, we need to
specify the directory in which the vensim file resides, the name of the vensim
file and the name of the model.
wd = r'./models/vensim example'
model = VensimModel("simpleModel", wd=wd, model_file=r'\model.vpm')
Next, we can specify the uncertainties and the outcomes.
1model.uncertainties = [RealParameter("x11", 0, 2.5),
2 RealParameter("x12", -2.5, 2.5)]
3
4
5model.outcomes = [TimeSeriesOutcome('a')]
Note that we are using a TimeSeriesOutcome, because vensim results are time
series. We can now simply run this model by calling
perform_experiments().
with MultiprocessingEvaluator(model) as evaluator:
results = evaluator.perform_experiments(1000)
We now use a evaluator, which ensures that the code is executed in parallel.
Is it generally good practice to first run a model a small number of times sequentially prior to running in parallel. In this way, bugs etc. can be spotted more easily. To further help with keeping track of what is going on, it is also good practice to make use of the logging functionality provided by the workbench
ema_logging.log_to_stderr(ema_logging.INFO)
Typically, this line appears at the start of the script. When executing the code, messages on progress or on errors will be shown.
The complete code
1"""Basic example of how to connect a Vensim model to the ema_workbench."""
2
3# Created on 3 Jan. 2011
4#
5# This file illustrated the use the EMA classes for a contrived vensim
6# example
7
8from ema_workbench import (
9 RealParameter,
10 TimeSeriesOutcome,
11 ema_logging,
12 perform_experiments,
13)
14from ema_workbench.connectors.vensim import VensimModel
15
16if __name__ == "__main__":
17 # turn on logging
18 ema_logging.log_to_stderr(ema_logging.INFO)
19
20 # instantiate a model
21 wd = "./models/vensim example"
22 vensim_model = VensimModel("simple_model", wd=wd, model_file="model.vpm")
23 vensim_model.uncertainties = [
24 RealParameter("x11", 0, 2.5),
25 RealParameter("x12", -2.5, 2.5),
26 ]
27
28 vensim_model.outcomes = [TimeSeriesOutcome("a")]
29
30 results = perform_experiments(vensim_model, 1000)
A simple model in Excel
In order to perform EMA on an Excel model, one can use the
ExcelModel. This base
class makes uses of naming cells in Excel to refer to them directly. That is,
we can assume that the names of the uncertainties correspond to named cells
in Excel, and similarly, that the names of the outcomes correspond to named
cells or ranges of cells in Excel. When using this class, make sure that
the decimal separator and thousands separator are set correctly in Excel. This
can be checked via file > options > advanced. These separators should follow
the anglo saxon convention.
1"""Illustration of the use the EMA classes for a model in Excel.
2
3It uses the excel file provided by
4`A. Sharov <https://home.comcast.net/~sharov/PopEcol/lec10/fullmod.html>`_
5
6This excel file implements a simple predator prey model.
7
8"""
9
10from ema_workbench import (
11 RealParameter,
12 TimeSeriesOutcome,
13 ema_logging,
14 perform_experiments,
15)
16from ema_workbench.connectors.excel import ExcelModel
17from ema_workbench.em_framework.evaluators import MultiprocessingEvaluator
18
19# Created on 27 Jul. 2011
20#
21# .. codeauthor:: jhkwakkel <j.h.kwakkel (at) tudelft (dot) nl>
22
23
24if __name__ == "__main__":
25 ema_logging.log_to_stderr(level=ema_logging.INFO)
26
27 model = ExcelModel(
28 "predatorPrey", wd="./models/excelModel", model_file="excel example.xlsx"
29 )
30 model.uncertainties = [
31 RealParameter("K2", 0.01, 0.2),
32 # we can refer to a cell in the normal way
33 # we can also use named cells
34 RealParameter("KKK", 450, 550),
35 RealParameter("rP", 0.05, 0.15),
36 RealParameter("aaa", 0.00001, 0.25),
37 RealParameter("tH", 0.45, 0.55),
38 RealParameter("kk", 0.1, 0.3),
39 ]
40
41 # specification of the outcomes
42 model.outcomes = [
43 TimeSeriesOutcome("B4:B1076"),
44 # we can refer to a range in the normal way
45 TimeSeriesOutcome("P_t"),
46 ] # we can also use named range
47
48 # name of the sheet
49 model.default_sheet = "Sheet1"
50
51 with MultiprocessingEvaluator(model) as evaluator:
52 results = perform_experiments(
53 model, 100, reporting_interval=1, evaluator=evaluator
54 )
The example is relatively straight forward. We instantiate an excel model, we
specify the uncertainties and the outcomes. We also need to specify the sheet
in excel on which the model resides. Next we can call
perform_experiments().
Warning
when using named cells. Make sure that the names are defined at the sheet level and not at the workbook level
A more elaborate example: Mexican Flu
This example is derived from Pruyt & Hamarat (2010). This paper presents a small exploratory System Dynamics model related to the dynamics of the 2009 flu pandemic, also known as the Mexican flu, swine flu, or A(H1N1)v. The model was developed in May 2009 in order to quickly foster understanding about the possible dynamics of this new flu variant and to perform rough-cut policy explorations. Later, the model was also used to further develop and illustrate Exploratory Modelling and Analysis.
Mexican Flu: the basic model
In the first days, weeks and months after the first reports about the outbreak of a new flu variant in Mexico and the USA, much remained unknown about the possible dynamics and consequences of the at the time plausible/imminent epidemic/pandemic of the new flu variant, first known as Swine or Mexican flu and known today as Influenza A(H1N1)v.
The exploratory model presented here is small, simple, high-level, data-poor (no complex/special structures nor detailed data beyond crude guestimates), and history-poor.
The modelled world is divided in three regions: the Western World, the densely populated Developing World, and the scarcely populated Developing World. Only the two first regions are included in the model because it is assumed that the scarcely populated regions are causally less important for dynamics of flu pandemics. Below, the figure shows the basic stock-and-flow structure. For a more elaborate description of the model, see Pruyt & Hamarat (2010).
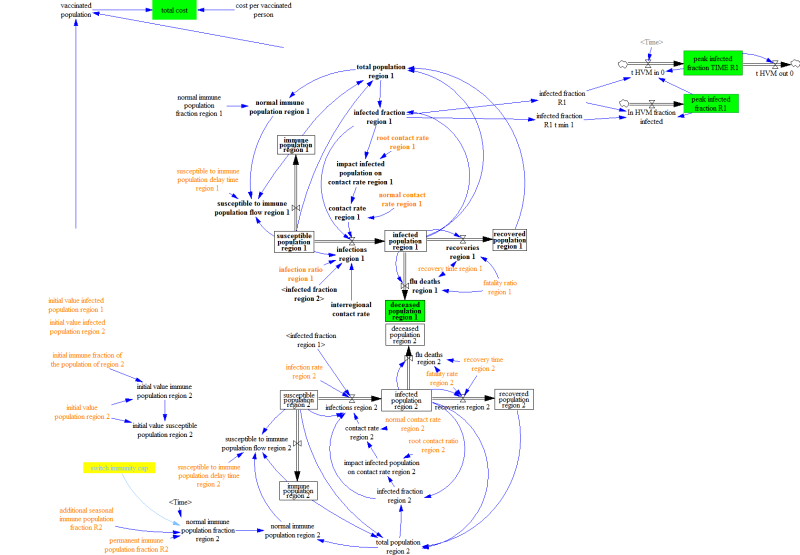
Given the various uncertainties about the exact characteristics of the flu, including its fatality rate, the contact rate, the susceptibility of the population, etc. the flu case is an ideal candidate for EMA. One can use EMA to explore the kinds of dynamics that can occur, identify undesirable dynamic, and develop policies targeted at the undesirable dynamics.
In the original paper, Pruyt & Hamarat (2010). recoded the model in Python and performed the analysis in that way. Here we show how the EMA workbench can be connected to Vensim directly.
The flu model was build in Vensim. We can thus use VensimModelS
as a base class.
We are interested in two outcomes:
deceased population region 1: the total number of deaths over the duration of the simulation.
peak infected fraction: the fraction of the population that is infected.
These are added to self.outcomes, using the TimeSeriesOutcome class.
The table below is adapted from Pruyt & Hamarat (2010).
It shows the uncertainties, and their bounds. These are added to
self.uncertainties as ParameterUncertainty
instances.
Parameter |
Lower Limit |
Upper Limit |
|---|---|---|
additional seasonal immune population fraction region 1 |
0.0 |
0.5 |
additional seasonal immune population fraction region 2 |
0.0 |
0.5 |
fatality ratio region 1 |
0.0001 |
0.1 |
fatality ratio region 2 |
0.0001 |
0.1 |
initial immune fraction of the population of region 1 |
0.0 |
0.5 |
initial immune fraction of the population of region 2 |
0.0 |
0.5 |
normal interregional contact rate |
0.0 |
0.9 |
permanent immune population fraction region 1 |
0.0 |
0.5 |
permanent immune population fraction region 2 |
0.0 |
0.5 |
recovery time region 1 |
0.2 |
0.8 |
recovery time region 2 |
0.2 |
0.8 |
root contact rate region 1 |
1.0 |
10.0 |
root contact rate region 2 |
1.0 |
10.0 |
infection ratio region 1 |
0.0 |
0.1 |
infection ratio region 2 |
0.0 |
0.1 |
normal contact rate region 1 |
10 |
200 |
normal contact rate region 2 |
10 |
200 |
Together, this results in the following code:
1"""No policy example of flu model.
2
3This module shows how you can use vensim models directly
4instead of coding the model in Python. The underlying case
5is the same as used in fluExample
6
7"""
8
9from ema_workbench import (
10 MultiprocessingEvaluator,
11 RealParameter,
12 TimeSeriesOutcome,
13 ema_logging,
14 perform_experiments,
15 save_results,
16)
17from ema_workbench.connectors.vensim import VensimModel
18
19# Created on 20 May, 2011
20#
21# .. codeauthor:: jhkwakkel <j.h.kwakkel (at) tudelft (dot) nl>
22# epruyt <e.pruyt (at) tudelft (dot) nl>
23
24
25if __name__ == "__main__":
26 ema_logging.log_to_stderr(ema_logging.INFO)
27
28 model = VensimModel(
29 "flu", wd=r"./models/flu", model_file=r"FLUvensimV1basecase.vpm"
30 )
31
32 # outcomes
33 model.outcomes = [
34 TimeSeriesOutcome("deceased_population_region_1"),
35 TimeSeriesOutcome("infected_fraction_R1"),
36 ]
37
38 # Plain Parametric Uncertainties
39 model.uncertainties = [
40 RealParameter(
41 "additional_seasonal_immune_population_fraction_R1",
42 0,
43 0.5,
44 ),
45 RealParameter(
46 "additional_seasonal_immune_population_fraction_R2",
47 0,
48 0.5,
49 ),
50 RealParameter(
51 "fatality_ratio_region_1",
52 0.0001,
53 0.1,
54 ),
55 RealParameter(
56 "fatality_rate_region_2",
57 0.0001,
58 0.1,
59 ),
60 RealParameter(
61 "initial_immune_fraction_of_the_population_of_region_1",
62 0,
63 0.5,
64 ),
65 RealParameter(
66 "initial_immune_fraction_of_the_population_of_region_2",
67 0,
68 0.5,
69 ),
70 RealParameter(
71 "normal_interregional_contact_rate",
72 0,
73 0.9,
74 ),
75 RealParameter(
76 "permanent_immune_population_fraction_R1",
77 0,
78 0.5,
79 ),
80 RealParameter(
81 "permanent_immune_population_fraction_R2",
82 0,
83 0.5,
84 ),
85 RealParameter("recovery_time_region_1", 0.1, 0.75),
86 RealParameter("recovery_time_region_2", 0.1, 0.75),
87 RealParameter(
88 "susceptible_to_immune_population_delay_time_region_1",
89 0.5,
90 2,
91 ),
92 RealParameter(
93 "susceptible_to_immune_population_delay_time_region_2",
94 0.5,
95 2,
96 ),
97 RealParameter(
98 "root_contact_rate_region_1",
99 0.01,
100 5,
101 ),
102 RealParameter(
103 "root_contact_ratio_region_2",
104 0.01,
105 5,
106 ),
107 RealParameter(
108 "infection_ratio_region_1",
109 0,
110 0.15,
111 ),
112 RealParameter("infection_rate_region_2", 0, 0.15),
113 RealParameter(
114 "normal_contact_rate_region_1",
115 10,
116 100,
117 ),
118 RealParameter(
119 "normal_contact_rate_region_2",
120 10,
121 200,
122 ),
123 ]
124
125 nr_experiments = 1000
126 with MultiprocessingEvaluator(model) as evaluator:
127 results = perform_experiments(model, nr_experiments, evaluator=evaluator)
128
129 save_results(results, "./data/1000 flu cases no policy.tar.gz")
We have now instantiated the model, specified the uncertain factors and outcomes
and run the model. We now have generated a dataset of results and can proceed to
analyse the results using various analysis scripts. As a first step, one can
look at the individual runs using a line plot using lines().
See plotting for some more visualizations using results from performing
EMA on FluModel.
1import matplotlib.pyplot as plt
2from ema_workbench.analysis.plotting import lines
3
4figure = lines(results, density=True) #show lines, and end state density
5plt.show() #show figure
generates the following figure:
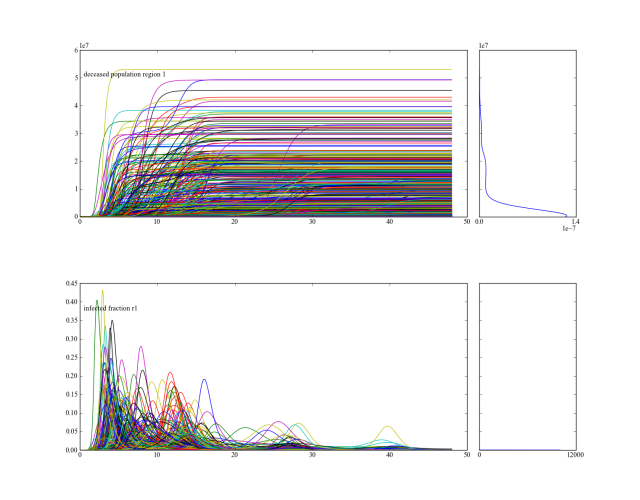
From this figure, one can deduce that across the ensemble of possible futures, there is a subset of runs with a substantial amount of deaths. We can zoom in on those cases, identify their conditions for occurring, and use this insight for policy design.
For further analysis, it is generally convenient, to generate the results for a series of experiments and save these results. One can then use these saved results in various analysis scripts.
from ema_workbench import save_results
save_results(results, './1000 runs.tar.gz')
The above code snippet shows how we can use save_results() for
saving the results of our experiments. save_results() stores the as
csv files in a tarball.
Mexican Flu: policies
For this paper, policies were developed by using the system understanding of the analysts.
static policy
adaptive policy
running the policies
In order to be able to run the models with the policies and to compare their results with the no policy case, we need to specify the policies
1#add policies
2policies = [Policy('no policy',
3 model_file=r'/FLUvensimV1basecase.vpm'),
4 Policy('static policy',
5 model_file=r'/FLUvensimV1static.vpm'),
6 Policy('adaptive policy',
7 model_file=r'/FLUvensimV1dynamic.vpm')
8 ]
In this case, we have chosen to have the policies implemented in separate
vensim files. Policies require a name, and can take any other keyword
arguments you like. If the keyword matches an attribute on the model object,
it will be updated, so model_file is an attribute on the vensim model. When
executing the policies, we update this attribute for each policy. We can pass
these policies to perform_experiment() as an additional keyword
argument
results = perform_experiments(model, 1000, policies=policies)
We can now proceed in the same way as before, and perform a series of experiments. Together, this results in the following code:
1"""A showcase of a mexican flu model with Vensim.
2
3This module shows how you can use vensim models directly
4instead of coding the model in Python. The underlying case
5is the same as used in example_flu.py
6
7
8"""
9
10# Created on 20 May, 2011
11# .. codeauthor:: jhkwakkel <j.h.kwakkel (at) tudelft (dot) nl>
12# epruyt <e.pruyt (at) tudelft (dot) nl>
13
14import numpy as np
15
16from ema_workbench import (
17 RealParameter,
18 Sample,
19 ScalarOutcome,
20 TimeSeriesOutcome,
21 ema_logging,
22 perform_experiments,
23 save_results,
24)
25from ema_workbench.connectors.vensim import VensimModel
26
27if __name__ == "__main__":
28 ema_logging.log_to_stderr(ema_logging.INFO)
29
30 model = VensimModel(
31 "fluCase", wd=r"./models/flu", model_file=r"FLUvensimV1basecase.vpm"
32 )
33
34 # outcomes
35 model.outcomes = [
36 TimeSeriesOutcome("deceased_population_region_1"),
37 TimeSeriesOutcome("infected_fraction_R1"),
38 ScalarOutcome(
39 "max_infection_fraction",
40 function=np.max,
41 variable_name="infected_fraction_R1",
42 ),
43 ]
44
45 # Plain Parametric Uncertainties
46 model.uncertainties = [
47 RealParameter("additional_seasonal_immune_population_fraction_R1", 0, 0.5),
48 RealParameter(
49 "additional_seasonal_immune_population_fraction_R2",
50 0,
51 0.5,
52 ),
53 RealParameter(
54 "fatality_ratio_region_1",
55 0.0001,
56 0.1,
57 ),
58 RealParameter(
59 "fatality_rate_region_2",
60 0.0001,
61 0.1,
62 ),
63 RealParameter(
64 "initial_immune_fraction_of_the_population_of_region_1",
65 0,
66 0.5,
67 ),
68 RealParameter(
69 "initial_immune_fraction_of_the_population_of_region_2",
70 0,
71 0.5,
72 ),
73 RealParameter(
74 "normal_interregional_contact_rate",
75 0,
76 0.9,
77 ),
78 RealParameter(
79 "permanent_immune_population_fraction_R1",
80 0,
81 0.5,
82 ),
83 RealParameter(
84 "permanent_immune_population_fraction_R2",
85 0,
86 0.5,
87 ),
88 RealParameter("recovery_time_region_1", 0.1, 0.75),
89 RealParameter("recovery_time_region_2", 0.1, 0.75),
90 RealParameter("susceptible_to_immune_population_delay_time_region_1", 0.5, 2),
91 RealParameter("susceptible_to_immune_population_delay_time_region_2", 0.5, 2),
92 RealParameter("root_contact_rate_region_1", 0.01, 5),
93 RealParameter("root_contact_ratio_region_2", 0.01, 5),
94 RealParameter(
95 "infection_ratio_region_1",
96 0,
97 0.15,
98 ),
99 RealParameter("infection_rate_region_2", 0, 0.15),
100 RealParameter(
101 "normal_contact_rate_region_1",
102 10,
103 100,
104 ),
105 RealParameter(
106 "normal_contact_rate_region_2",
107 10,
108 200,
109 ),
110 ]
111
112 # add policies
113 policies = [
114 Sample("no policy", model_file=r"FLUvensimV1basecase.vpm"),
115 Sample("static policy", model_file=r"FLUvensimV1static.vpm"),
116 Sample("adaptive policy", model_file=r"FLUvensimV1dynamic.vpm"),
117 ]
118
119 results = perform_experiments(model, 1000, policies=policies)
120 save_results(results, "./data/1000 flu cases with policies.tar.gz")
comparison of results
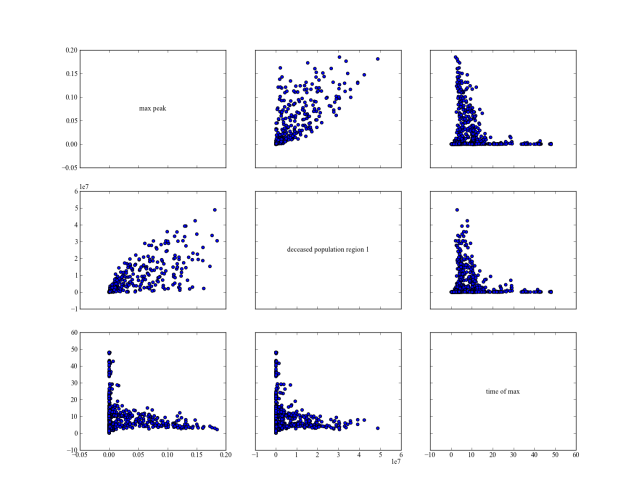
Using the following script, we reproduce figures similar to the 3D figures
in Pruyt & Hamarat (2010).
But using pairs_scatter(). It shows for the three different policies
their behavior on the total number of deaths, the height of the highest peak
of the pandemic, and the point in time at which this peak was reached.
1"""Basic example pairplot.."""
2
3# Created on 20 sep. 2011
4#
5# .. codeauthor:: jhkwakkel <j.h.kwakkel (at) tudelft (dot) nl>
6
7import matplotlib.pyplot as plt
8import numpy as np
9
10from ema_workbench import ema_logging, load_results
11from ema_workbench.analysis.pairs_plotting import (
12 pairs_density,
13 pairs_lines,
14 pairs_scatter,
15)
16
17ema_logging.log_to_stderr(level=ema_logging.DEFAULT_LEVEL)
18
19# load the data
20fh = "./data/1000 flu cases no policy.tar.gz"
21experiments, outcomes = load_results(fh)
22
23# transform the results to the required format
24# that is, we want to know the max peak and the casualties at the end of the
25# run
26tr = {}
27
28# get time and remove it from the dict
29time = outcomes.pop("TIME")
30
31for key, value in outcomes.items():
32 if key == "deceased_population_region_1":
33 tr[key] = value[:, -1] # we want the end value
34 else:
35 # we want the maximum value of the peak
36 max_peak = np.max(value, axis=1)
37 tr["max peak"] = max_peak
38
39 # we want the time at which the maximum occurred
40 # the code here is a bit obscure, I don't know why the transpose
41 # of value is needed. This however does produce the appropriate results
42 logical = np.max(value, axis=1) == value.T
43 tr["time of max"] = time[logical.T]
44
45pairs_scatter(experiments, tr, filter_scalar=False)
46pairs_lines(experiments, outcomes)
47pairs_density(experiments, tr, filter_scalar=False)
48plt.show()
no policy
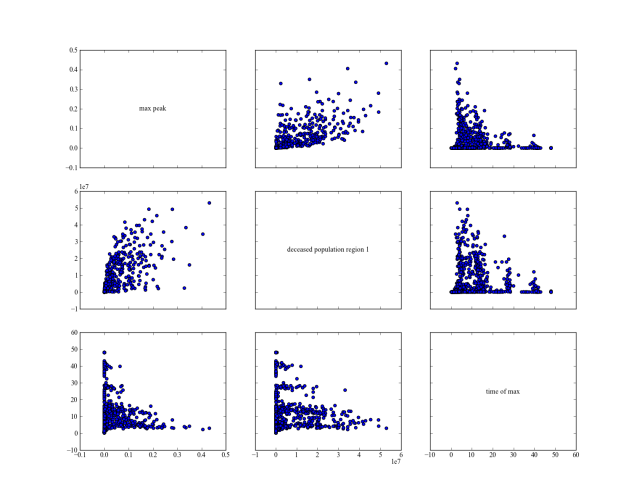
static policy
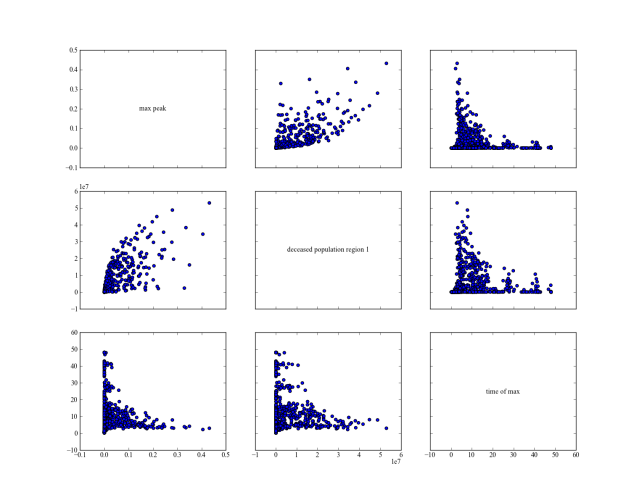
adaptive policy