Directed search¶
This is the third turial in a series showcasing the functionality of the Exploratory Modeling workbench. Exploratory modeling entails investigating the way in which uncertainty and/or policy levers map to outcomes. To investigate these mappings, we can either use sampling based strategies (open exploration) or optimization based strategies (directed search).
In this tutorial, I will demonstrate in more detail how to use the workbench for directed search. We are using the same example as in the previous tutorials. When using optimization, it is critical that you specify for each Scalar Outcome the direction in which it should move. There are three possibilities: info which is ignored, maximize, and minimize. If the kind keyword argument is not specified, it defaults to info.
[1]:
from ema_workbench import RealParameter, ScalarOutcome, Constant, Model
from dps_lake_model import lake_model
model = Model("lakeproblem", function=lake_model)
# specify uncertainties
model.uncertainties = [
RealParameter("b", 0.1, 0.45),
RealParameter("q", 2.0, 4.5),
RealParameter("mean", 0.01, 0.05),
RealParameter("stdev", 0.001, 0.005),
RealParameter("delta", 0.93, 0.99),
]
# set levers
model.levers = [
RealParameter("c1", -2, 2),
RealParameter("c2", -2, 2),
RealParameter("r1", 0, 2),
RealParameter("r2", 0, 2),
RealParameter("w1", 0, 1),
]
# specify outcomes
model.outcomes = [
ScalarOutcome("max_P", ScalarOutcome.MINIMIZE),
ScalarOutcome("utility", ScalarOutcome.MAXIMIZE),
ScalarOutcome("inertia", ScalarOutcome.MAXIMIZE),
ScalarOutcome("reliability", ScalarOutcome.MAXIMIZE),
]
# override some of the defaults of the model
model.constants = [
Constant("alpha", 0.41),
Constant("nsamples", 150),
Constant("myears", 100),
]
Using directed search with the ema_workbench requires platypus-opt. Please check the installation suggestions provided in the readme of the github repository. I personally either install from github directly
pip git+https://github.com/Project-Platypus/Platypus.git
or through pip
pip install platypus-opt
One note of caution: don’t install platypus, but platypus-opt. There exists a python package on pip called platypus, but that is quite a different kind of libary.
There are three ways in which we can use optimization in the workbench: 1. Search over the decision levers, conditional on a reference scenario 2. Search over the uncertain factors, conditional on a reference policy 3. Search over the decision levers given a set of scenarios
Search over levers¶
Directed search is most often used to search over the decision levers in order to find good candidate strategies. This is for example the first step in the Many Objective Robust Decision Making process. This is straightforward to do with the workbench using the optimize method. Note that I have kept the number of functional evaluations (nfe) very low. In real applications this should be substantially higher and be based on convergence considerations which are demonstrated below.
[2]:
from ema_workbench import MultiprocessingEvaluator, ema_logging
ema_logging.log_to_stderr(ema_logging.INFO)
with MultiprocessingEvaluator(model) as evaluator:
results = evaluator.optimize(
nfe=250,
searchover="levers",
epsilons=[
0.1,
]
* len(model.outcomes),
)
[MainProcess/INFO] pool started with 12 workers
298it [00:07, 42.43it/s]
[MainProcess/INFO] optimization completed, found 6 solutions
[MainProcess/INFO] terminating pool
the results from optimize is a DataFrame with the decision variables and outcomes of interest.
[3]:
results
[3]:
| c1 | c2 | r1 | r2 | w1 | max_P | utility | inertia | reliability | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.031532 | 0.184650 | 0.280885 | 0.410156 | 0.367589 | 0.094885 | 0.250233 | 0.990000 | 1.000000 |
| 1 | -0.625142 | 0.098499 | 1.047069 | 0.913895 | 0.079976 | 2.283907 | 1.378241 | 0.985533 | 0.206533 |
| 2 | 0.686334 | 0.557664 | 1.017384 | 0.807999 | 0.496470 | 2.283759 | 1.001528 | 0.970933 | 0.310533 |
| 3 | 0.435289 | 0.350622 | 0.319505 | 0.624951 | 0.026242 | 0.197131 | 0.537310 | 0.990000 | 1.000000 |
| 4 | 1.947359 | -0.622528 | 1.619746 | 1.863076 | 0.418746 | 2.283625 | 1.778130 | 0.990000 | 0.070000 |
| 5 | 0.629075 | -0.076368 | 1.666986 | 0.488599 | 0.673219 | 2.283672 | 1.631001 | 0.980000 | 0.110000 |
Specifying constraints¶
It is possible to specify a constrained optimization problem. A model can have one or more constraints. A constraint can be applied to the model input parameters (both uncertainties and levers), and/or outcomes. A constraint is essentially a function that should return the distance from the feasibility threshold. The distance should be 0 if the constraint is met.
[4]:
from ema_workbench import Constraint
constraints = [
Constraint("max pollution", outcome_names="max_P", function=lambda x: max(0, x - 1))
]
[5]:
from ema_workbench import MultiprocessingEvaluator
from ema_workbench import ema_logging
ema_logging.log_to_stderr(ema_logging.INFO)
with MultiprocessingEvaluator(model) as evaluator:
results = evaluator.optimize(
nfe=250,
searchover="levers",
epsilons=[
0.1,
]
* len(model.outcomes),
constraints=constraints,
)
[MainProcess/INFO] pool started with 12 workers
298it [00:07, 42.38it/s]
[MainProcess/INFO] optimization completed, found 3 solutions
[MainProcess/INFO] terminating pool
[6]:
results
[6]:
| c1 | c2 | r1 | r2 | w1 | max_P | utility | inertia | reliability | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.242378 | 0.463484 | 1.707600 | 0.404997 | 0.886919 | 0.215327 | 0.555460 | 0.99 | 1.0 |
| 1 | 0.242378 | 0.343609 | 1.707600 | 0.434568 | 0.949529 | 0.092854 | 0.234231 | 0.99 | 1.0 |
| 2 | 0.042579 | 0.672822 | 0.957689 | 1.814246 | 0.168521 | 0.146712 | 0.419054 | 0.99 | 1.0 |
Tracking convergence¶
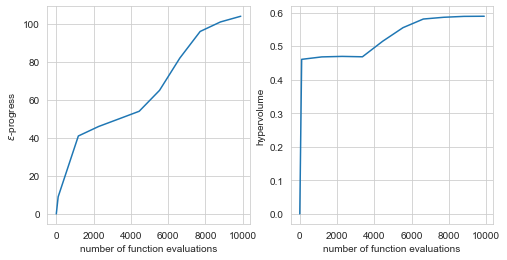
An important part of using many-objective evolutionary algorithms is to carefully monitor whether they have converged. Various different metrics can be used for this. The workbench supports two useful metrics known as hypervolume and epsilon progress.
[7]:
from ema_workbench.em_framework.optimization import HyperVolume, EpsilonProgress
convergence_metrics = [
HyperVolume(minimum=[0, 0, 0, 0], maximum=[1, 1.01, 1.01, 1.01]),
EpsilonProgress(),
]
with MultiprocessingEvaluator(model) as evaluator:
results, convergence = evaluator.optimize(
nfe=10000,
searchover="levers",
epsilons=[
0.05,
]
* len(model.outcomes),
convergence=convergence_metrics,
constraints=constraints,
)
fig, (ax1, ax2) = plt.subplots(ncols=2, sharex=True, figsize=(8, 4))
ax1.plot(convergence.nfe, convergence.epsilon_progress)
ax1.set_ylabel("$\epsilon$-progress")
ax2.plot(convergence.nfe, convergence.hypervolume)
ax2.set_ylabel("hypervolume")
ax1.set_xlabel("number of function evaluations")
ax2.set_xlabel("number of function evaluations")
plt.show()
[MainProcess/INFO] pool started with 12 workers
10010it [02:17, 73.02it/s]
[MainProcess/INFO] optimization completed, found 16 solutions
[MainProcess/INFO] terminating pool
Changing the reference scenario¶
The workbench offers control over the reference scenario or policy under which you are performing the optimization. This makes it easy to aply multi-scenario MORDM (Watson & Kasprzyk, 2017). Alternatively, you can also use it to change the policy for which you are applying worst case scenario discovery (see below).
reference = Scenario('reference', b=0.4, q=2, mean=0.02, stdev=0.01)
with MultiprocessingEvaluator(lake_model) as evaluator:
results = evaluator.optimize(searchover='levers', nfe=1000,
epsilons=[0.1, ]*len(lake_model.outcomes),
reference=reference)
Search over uncertainties: worst case discovery¶
Up till now, the focus has been on applying search to find promising candidate strategies. That is, we search through the lever space. However, there might also be good reasons to search through the uncertainty space. For example to search for worst case scenarios (Halim et al, 2015). This is easily achieved as shown below. We change the kind attribute on each outcome so that we search for the worst outcome and specify that we would like to search over the uncertainties instead of the levers.
Any of the foregoing additions such as constraints or converence work as shown above. Note that if you would like to to change the reference policy, reference should be a Policy object rather than a Scenario object.
[8]:
# change outcomes so direction is undesirable
minimize = ScalarOutcome.MINIMIZE
maximize = ScalarOutcome.MAXIMIZE
for outcome in model.outcomes:
if outcome.kind == minimize:
outcome.kind = maximize
else:
outcome.kind = minimize
with MultiprocessingEvaluator(model) as evaluator:
results = evaluator.optimize(
nfe=1000,
searchover="uncertainties",
epsilons=[
0.1,
]
* len(model.outcomes),
)
[MainProcess/INFO] pool started with 12 workers
1090it [00:18, 60.52it/s]
[MainProcess/INFO] optimization completed, found 7 solutions
[MainProcess/INFO] terminating pool
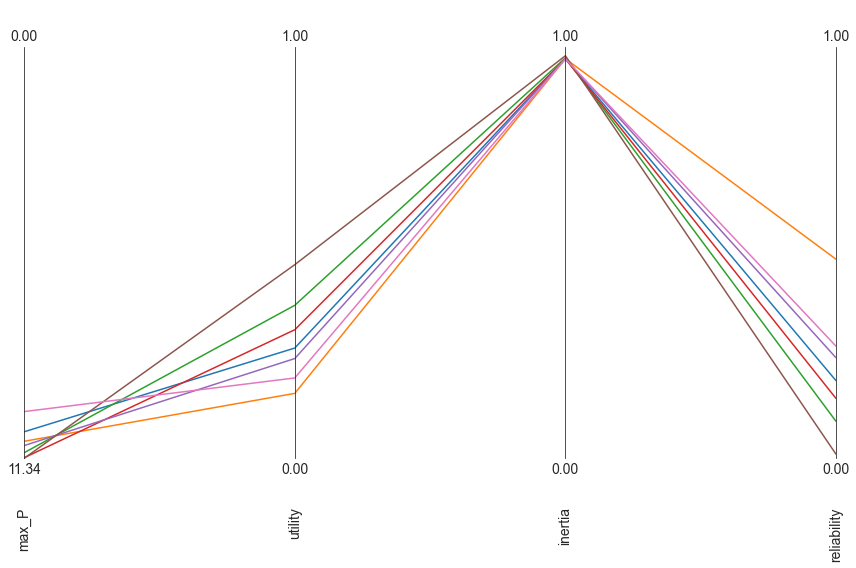
Parallel coordinate plots¶
The workbench comes with support for making parallel axis plots through the parcoords module. This module offers a parallel axes object on which we can plot data. The typical workflow is to first instantiate this parallel axes object given a pandas dataframe with the upper and lower limits for each axes. Next, one or more datasets can be plotted on this axes. Any dataframe passed to the plot method will be normalized using the limits passed first. We can also invert any of the axes to ensure that the desirable direction is the same for all axes.
[9]:
from ema_workbench.analysis import parcoords
data = results.loc[:, [o.name for o in model.outcomes]]
limits = parcoords.get_limits(data)
limits.loc[0, ["utility", "inertia", "reliability", "max_P"]] = 0
limits.loc[1, ["utility", "inertia", "reliability"]] = 1
paraxes = parcoords.ParallelAxes(limits)
paraxes.plot(data)
paraxes.invert_axis("max_P")
plt.show()
Robust Search¶
In the foregoing, we have been using optimization over levers or uncertainties, while assuming a reference scenario or policy. However, we can also formulate a robust many objective optimization problem, were we are going to search over the levers for solutions that have robust performance over a set of scenarios. To do this with the workbench, there are several steps that one has to take.
First, we need to specify our robustness metrics. A robustness metric takes as input the performance of a candidate policy over a set of scenarios and returns a single robustness score. For a more in depth overview, seeMcPhail et al. (2018). In case of the workbench, we can use the ScalarOutcome class for this. We need to specify the name of the robustness metric a function that takes as input a numpy array and returns a single number, and the model outcome to which this function should be applied.
Below, we use a percentile based robustness metric, which we apply to each model outcome.
[10]:
import functools
percentile10 = functools.partial(np.percentile, q=10)
percentile90 = functools.partial(np.percentile, q=90)
MAXIMIZE = ScalarOutcome.MAXIMIZE
MINIMIZE = ScalarOutcome.MINIMIZE
robustnes_functions = [
ScalarOutcome(
"90th percentile max_p",
kind=MINIMIZE,
variable_name="max_P",
function=percentile90,
),
ScalarOutcome(
"10th percentile reliability",
kind=MAXIMIZE,
variable_name="reliability",
function=percentile10,
),
ScalarOutcome(
"10th percentile inertia",
kind=MAXIMIZE,
variable_name="inertia",
function=percentile10,
),
ScalarOutcome(
"10th percentile utility",
kind=MAXIMIZE,
variable_name="utility",
function=percentile10,
),
]
Next, we have to generate the scenarios we want to use. Below we generate 50 scenarios, which we will keep fixed over the optimization. The exact number of scenarios to use is to be established through trial and error. Typically it involves balancing computational costs of more scenarios, with the stability of the robustness metric over the number of scenarios
[11]:
from ema_workbench.em_framework import sample_uncertainties
n_scenarios = 50
scenarios = sample_uncertainties(model, n_scenarios)
With the robustness metrics specified, and the scenarios, sampled, we can now perform robust many-objective optimization. Below is the code that one would run. Note that this is computationally very expensive since each candidate solution is going to be run for fifty scenarios before we can calculate the robustness for each outcome of interest.
nfe = int(1e6)
with MultiprocessingEvaluator(model) as evaluator:
robust_results = evaluator.robust_optimize(robustnes_functions, scenarios,
nfe=nfe, epsilons=[0.05,]*len(robustnes_functions))
[ ]: